Resilience in cloud computing is the cornerstone of maintaining reliable and uninterrupted digital services. It is the system’s ability to recover from failures and continue operating without significant downtime or data loss. In the dynamic environment of cloud computing, where applications and infrastructure are prone to disruptions, resilience ensures that businesses meet user expectations, maintain trust, and stay competitive.
AWS (Amazon Web Services) provides a robust framework and a suite of tools to design and implement resilient architectures. This guide explores key principles, actionable steps, and AWS services that enable the creation of systems designed to withstand failures, recover efficiently, and deliver consistent performance.
Resilience involves multiple dimensions that collectively ensure robust system performance. Fault Tolerance refers to systems that can continue functioning despite component failures, ensuring uninterrupted services. High Availability means downtime is minimized, and services remain accessible to users at all times. Disaster Recovery allows systems to recover swiftly from catastrophic events, protecting data and restoring operations. The goal is to proactively prepare for potential failures and mitigate their impact on users and business operations.
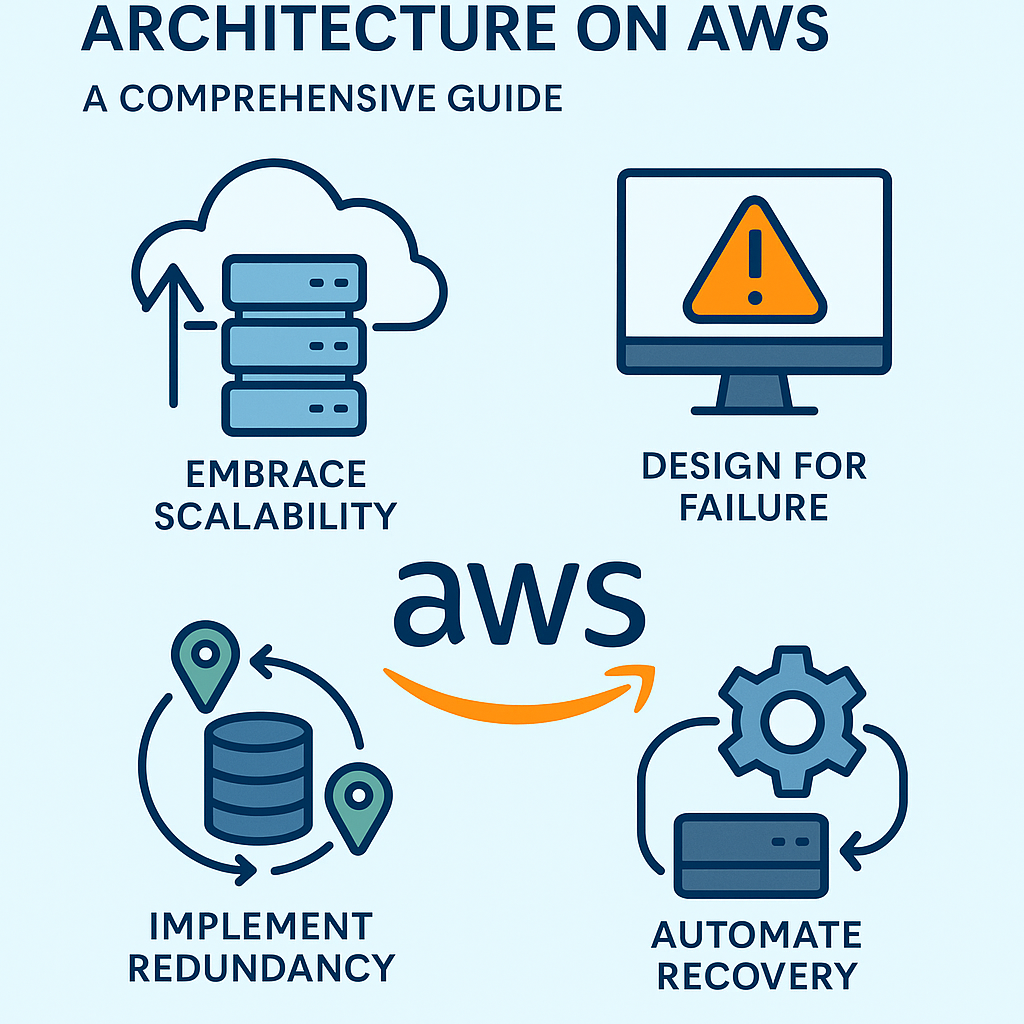
There are several design principles for resilient architectures on AWS. Embrace Scalability: use services like Amazon EC2 Auto Scaling to dynamically adjust resources based on demand. Design for Failure: accept that failures are inevitable. Use AWS Fault Injection Simulator to test system robustness. Implement Redundancy: distribute resources across multiple Availability Zones or regions. Use Amazon RDS Multi-AZ for databases. Automate Recovery: use AWS Lambda for auto-restart and incident response automation. Use Managed Services: choose services like Amazon S3, DynamoDB, and ELB for built-in resilience features.
The following is a step-by-step guide to building a resilient architecture on AWS.
First, Set Up Multi-Region Deployment. Why: ensures service continuity even if an entire AWS region fails. How: use Amazon Route 53 for latency-based routing and DNS failover. Deploy in at least two regions to prevent regional outages. Second, Use Load Balancers for Traffic Distribution.
Why: prevents single points of failure by evenly distributing traffic. How: use ALB for HTTP/HTTPS traffic. Use NLB for low-latency, high-throughput traffic. Third, Implement Data Durability. Why: protect critical data from loss. How: use Amazon S3 with versioning and cross-region replication. Enable DynamoDB Streams for real-time replication. Use AWS Backup for automated backups. Fourth, Enable Auto Scaling. Why: automatically handles traffic spikes.
How: configure EC2 Auto Scaling Groups with CPU, memory, or custom metric triggers. Fifth, Leverage Serverless Architectures.
Why: reduces infrastructure management, increases resilience.
How: use AWS Lambda and API Gateway for stateless, scalable services. Sixth, Monitor and Respond Proactively.
Why: early issue detection prevents major outages.
How: use Amazon CloudWatch for metrics and alarms. Automate responses using AWS Systems Manager Incident Manager. Seventh, Secure Your Architecture. Why: resilience includes strong security.
How: use IAM roles with least privilege. Protect with AWS Shield Advanced. Encrypt data using AWS KMS.
Resilience can be applied to different workloads. For Web Applications, use Amazon CloudFront as CDN for latency and availability. Protect with AWS WAF against web exploits. For Databases, use Amazon Aurora Global Database for disaster recovery. Schedule snapshots using RDS backups. For Big Data Analytics, use Amazon EMR with fault-tolerant spot instances. Store in S3 with lifecycle policies.
A SaaS company hosting a collaboration platform improved resilience by implementing several strategies. In terms of Multi-Region Setup, they used Route 53 with deployments in US-East-1 and EU-West-1. For Data Replication, they used S3 cross-region replication and DynamoDB Global Tables. For Proactive Monitoring, they tracked metrics with CloudWatch and automated failover with Lambda. For Load Balancing and Scaling, ALB and Auto Scaling Groups handled traffic and demand spikes.
Cost Optimization Tips for Resilient Architectures include using Spot Instances for non-critical tasks, utilizing Savings Plans for predictable usage, and applying AWS Trusted Advisor suggestions to optimize resources.
Building a resilient architecture on AWS involves strategic planning, smart design, and using AWS services effectively. Proactively addressing failure, availability, and recovery ensures your systems are secure, scalable, and trusted. Start your resilience journey today by evaluating your infrastructure and applying these principles to achieve operational excellence.
Building a Resilient Architecture on AWS: A Comprehensive Guide
Resilience in cloud computing is the cornerstone of maintaining reliable and uninterrupted digital services. It is the system’s ability to recover from failures and continue operating without significant downtime or data loss. In the dynamic environment of cloud computing, where applications and infrastructure are prone to disruptions, resilience ensures that businesses meet user expectations, maintain trust, and stay competitive.
AWS (Amazon Web Services) provides a robust framework and a suite of tools to design and implement resilient architectures. This guide explores key principles, actionable steps, and AWS services that enable the creation of systems designed to withstand failures, recover efficiently, and deliver consistent performance.
Resilience involves multiple dimensions that collectively ensure robust system performance. Fault Tolerance refers to systems that can continue functioning despite component failures, ensuring uninterrupted services. High Availability means downtime is minimized, and services remain accessible to users at all times. Disaster Recovery allows systems to recover swiftly from catastrophic events, protecting data and restoring operations. The goal is to proactively prepare for potential failures and mitigate their impact on users and business operations.
There are several design principles for resilient architectures on AWS. Embrace Scalability: use services like Amazon EC2 Auto Scaling to dynamically adjust resources based on demand. Design for Failure: accept that failures are inevitable. Use AWS Fault Injection Simulator to test system robustness. Implement Redundancy: distribute resources across multiple Availability Zones or regions. Use Amazon RDS Multi-AZ for databases. Automate Recovery: use AWS Lambda for auto-restart and incident response automation. Use Managed Services: choose services like Amazon S3, DynamoDB, and ELB for built-in resilience features.
The following is a step-by-step guide to building a resilient architecture on AWS. First, Set Up Multi-Region Deployment. Why: ensures service continuity even if an entire AWS region fails. How: use Amazon Route 53 for latency-based routing and DNS failover. Deploy in at least two regions to prevent regional outages. Second, Use Load Balancers for Traffic Distribution. Why: prevents single points of failure by evenly distributing traffic. How: use ALB for HTTP/HTTPS traffic. Use NLB for low-latency, high-throughput traffic. Third, Implement Data Durability. Why: protect critical data from loss. How: use Amazon S3 with versioning and cross-region replication. Enable DynamoDB Streams for real-time replication. Use AWS Backup for automated backups. Fourth, Enable Auto Scaling. Why: automatically handles traffic spikes. How: configure EC2 Auto Scaling Groups with CPU, memory, or custom metric triggers. Fifth, Leverage Serverless Architectures. Why: reduces infrastructure management, increases resilience. How: use AWS Lambda and API Gateway for stateless, scalable services. Sixth, Monitor and Respond Proactively. Why: early issue detection prevents major outages. How: use Amazon CloudWatch for metrics and alarms. Automate responses using AWS Systems Manager Incident Manager. Seventh, Secure Your Architecture. Why: resilience includes strong security. How: use IAM roles with least privilege. Protect with AWS Shield Advanced. Encrypt data using AWS KMS.
Resilience can be applied to different workloads. For Web Applications, use Amazon CloudFront as CDN for latency and availability. Protect with AWS WAF against web exploits. For Databases, use Amazon Aurora Global Database for disaster recovery. Schedule snapshots using RDS backups. For Big Data Analytics, use Amazon EMR with fault-tolerant spot instances. Store in S3 with lifecycle policies.
A SaaS company hosting a collaboration platform improved resilience by implementing several strategies. In terms of Multi-Region Setup, they used Route 53 with deployments in US-East-1 and EU-West-1. For Data Replication, they used S3 cross-region replication and DynamoDB Global Tables. For Proactive Monitoring, they tracked metrics with CloudWatch and automated failover with Lambda. For Load Balancing and Scaling, ALB and Auto Scaling Groups handled traffic and demand spikes.
Cost Optimization Tips for Resilient Architectures include using Spot Instances for non-critical tasks, utilizing Savings Plans for predictable usage, and applying AWS Trusted Advisor suggestions to optimize resources.
Building a resilient architecture on AWS involves strategic planning, smart design, and using AWS services effectively. Proactively addressing failure, availability, and recovery ensures your systems are secure, scalable, and trusted. Start your resilience journey today by evaluating your infrastructure and applying these principles to achieve operational excellence.