
The Human Side of Data Science: Turning Numbers Into Real-World Impact
More Than Just Numbers Every day, billions of data points are generated, from the steps we take to the videos we watch, to the energy we use at home. To many, this is just information. But to a data scientist, it’s the beginning of a story, a story about people, behaviors, and the small patterns that can make a big difference in the world. In a world obsessed with numbers, it’s easy to forget that data is deeply human. Behind every data point is a heartbeat, a choice, or a moment of life. And that’s where the real power of data science begins. When Data Saved a City’s Breath In 2024, the city of Nairobi faced a growing crisis, air pollution levels were spiking, and hospitals were reporting an increase in respiratory illnesses among children. Traditional monitoring systems couldn’t keep up; they were too few, too slow, and too expensive.

Top Data Engineering Trends and Technologies Shaping 2025
Introduction Data engineering has evolved from simple ETL (Extract, Transform, Load) jobs to an advanced ecosystem of cloud-native pipelines, real-time analytics, and AI-driven automation. As data becomes the backbone of digital transformation, new tools and technologies are redefining how organizations collect, process, and leverage information. This post explores the biggest data engineering trends and technologies of 2025 that every tech team and data professional should keep an eye on. 1. Rise of Real-Time Data Pipelines Batch processing is no longer enough. Businesses now demand real-time insights to make instant decisions. Tools like Apache Kafka, Flink, and Spark Structured Streaming are leading the way, enabling continuous data ingestion and analysis from multiple sources. Trend Insight:Real-time architecture is becoming the new standard, especially for fintech, e-commerce, and IoT-driven industries. 2. DataOps and Automation Take Center Stage DataOps, often called the DevOps for data, focuses on streamlining data workflows through automation and collaboration.

Data Analyst vs. Data Scientist: Clearing the Confusion in Data Careers
In the fast-growing world of data, roles are evolving quickly. Two titles you’ll often hear are “Data Analyst” and “Data Scientist.” They’re sometimes used interchangeably but are they really the same? Let’s break it down, clear up the confusion, and understand how each role fits into the modern data-driven landscape. What is a Data Scientist? A Data Scientist is often seen as the problem-solver who works at the intersection of statistics, machine learning, and programming. Their job goes beyond just looking at data they build predictive models and create systems that can learn patterns. A Data Scientist typically:• Cleans and processes raw datasets.• Builds machine learning models for forecasting, recommendations, or classifications.• Uses programming languages like Python, R, or Julia.• Works on big data platforms and cloud solutions.• Helps companies predict future trends using advanced algorithms. Think of them as architects who design intelligent solutions that transform data into actionable

Python vs R: Know The Difference
Python vs R: Know The Difference The world is moving towards the next technological wonder with Data Science and Artificial Intelligence leading the way. If you’re aware of this world, then you know about the two programming languages that are always a matter of interest and debate: Python and R. Python An interpreted, high-level object-oriented programming language with simple, readable syntax. Python comes with built-in data structures and powerful libraries for data science like Scikit-learn, TensorFlow, and Pandas. Advantages Versatility: Supports multiple programming paradigms Open Source: Free with active community support Libraries: Extensive collection for data science Productivity: Great integration capabilities Embeddable: Can integrate with other languages Disadvantages Speed: Slower than compiled languages Mobile: Weak for Android/iOS development Memory: High RAM consumption Database: Underdeveloped access layers Threading: Limited by Global Interpreter Lock R A programming language for statistical computing and graphics. R comes with a wide range of statistical techniques
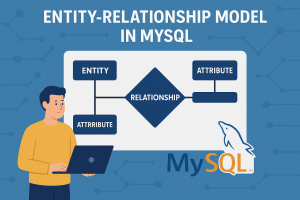
MySQL: Entity-Relationship Model
Entity-Relationship model or E R model is used to create a relationship between different attributes or entities. It describes the structure of the database with the help of the ER Diagram or Entity Relationship Diagram. ER model creates a simple design view of the data that makes the data easier to understand. Example: Here, we have a database COMPANY, and in this database, EMPLOYEE is the entity (table). The employee entity contains several attributes like EMP_ID, EMP_NAME, EMP_ADDRESS, EMP_DATE_OF_BIRTH, EMP_AGE, and EMP_CONTACT. ER Model Components 1. Entity The entity in DBMS can be a real-world object having conceptual reality and existence. Example: In a COMPANY database, the entity type is EMPLOYEE. Here employees are real-world persons that have some existence. Entity Types Strong Entity Entities that don’t depend on other entities. Contains a primary key. Represented by a single rectangular box. Example: EMPLOYEE with EMP_ID as primary key. Weak Entity